Here is my process for optimizing my Wordle guesses. Yes it’s been done before, but I was bored and had a little too much time on my hands.
For those unfamiliar, Wordle is a simple browser game where the objective is to guess a certain five-letter word in 6 or fewer guesses. Feedback is given in the form of coloured tiles that indicate if each letter exists in the word (yellow), if the letter is in the word and in the correct spot (green), or if the letter is not in the word (grey). Wordle reached viral popularity in early 2022, during which it was sold to The New York Times and is now hosted on their site.

My initial approach to playing Wordle was to begin each game with a guess that contained mostly vowels. “OUIJA” was my favored pick for a long time, but it was flawed in a few ways: 1) J is not a common letter, 2) the order of letters was not ideal; there are only a small number of five-letter words that begin with O, for example, and 3) the presence of vowels is only one step in determining the word, and may not be the best approach. My approach then shifted to determining which words had the highest probability of having letters in the correct spots.
I downloaded a text file from here that contained a list of the most common English words based on a database of TV and movie scripts. I extracted the five-letter words, excluding words that ended in “s”, “ed”, or “ing”, as these were most likely plurals, past tense, or present participles, respectively. (In hindsight, I may have lost some valid words, such as “OASIS”, due to this naïve filtering rule, but I am making the assumption that these cases are rare.) After this step, I had 1417 valid five-letter words.
Then I wrote a Python script that counted the number of occurrences of each letter in each spot. The result looked like this:

I went back to my list of 1417 words and iterated through them again, assigning scores to them based on the occurrence of each of their letters in that particular spot. I sorted the words by their score and exported the results to a .csv file.
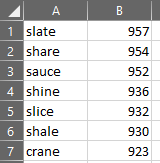
It appears that “SLATE” has the most common letters, and therefore has the highest probability of returning green-tiled letters when used as a first guess. But this is just one word, and unless you’re feeling lucky, you’re still a few steps away from being able to guess the actual word. So we need to go deeper.
What if we consider two words, each with unique letters? So for example, let’s take “SLATE” and go down the list of words, searching for the first word that does not share any letters with “SLATE”. Our answer is “CORNY”, with a score of 765 and a combined score of 1722. But is this the best two-word combination? I ran another Python script that calculated combined scores for each two-word combination with unique letters. Here are the results:
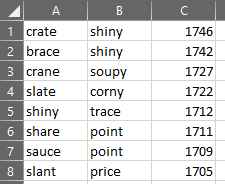
The top two-word combination was “CRATE” and “SHINY”. Based on this, I could see that my initial assumption about vowels was likely correct: using as many vowels as possible was not the ideal approach, at least statistically. Using these two words as opening guesses would ideally put me in a good spot to guess the rest of the letters.
Hey, did you guys know that you can play more than one Wordle at once? Like Quordle, where you play 4 Wordles at once? Or Octordle, with 8 Wordles? Or even Sedecordle, with 16 Wordles?
We need to go even deeper. Let’s check out what the best 3-word and 4-word combinations look like.
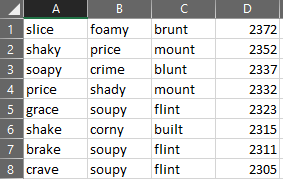
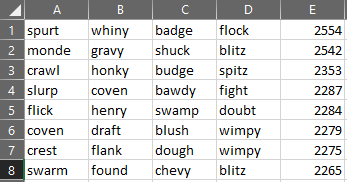
When calculating the 4-word combinations, I was beginning to run out of words that each had unique letters. That led me to wonder if there was another combination where some letters were reused that was ultimately more optimal than the combinations shown above. But at this point, it was around 2 am, so I decided to save those thoughts for another time.
I’ll be trying out these word combinations in my Wordle/Quordle/Octordle/Sedecordle games in the near future, hopefully with some success. Feel free to try them out as well and let me know how your games go!